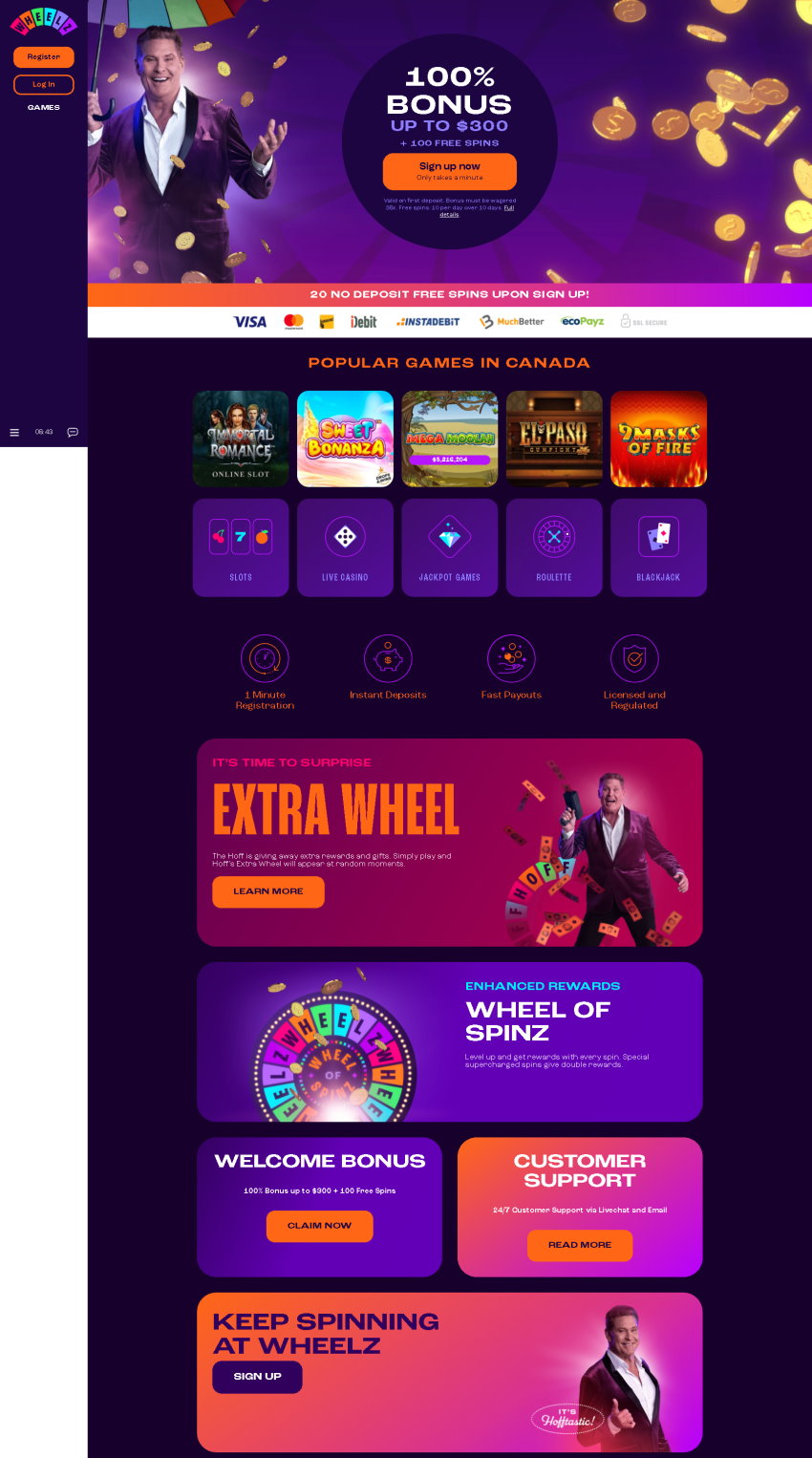
Wheelz Casino holds a license from Curacao and promises players a huge selection of games, fast payments and superior encryption technology. The casino offers a fun-filled and exhilarating platform for gamblers from around the world to enjoy a great selection of games and promotions as well as tournaments.
Wheelz Casino homepage displays the most popular games at the moment, allowing you to dive right into the excitement. The casino offers exciting promotions, delights the customers by an impressive selection of high-quality games of famous brands and accepts cryptocurrency of several types.
Wheelz Casino has been designed and built by professionals with vast experience in the field of gambling, a large development team and responsive support. The casino gives you a fun gaming experience as there is a large collection of great games onsite from trusted software developers.
Wheelz Casino is partnered with many of the best software providers in order to host the games and provide fun, exciting and profitable experience to their players. Some of the major development studios in the business are featured on the online casino dollar site, including NetEnt, Microgaming, iSoftBet, Quickspin, and Evolution Gaming. All of them are making sure that each release is created under the highest of standards and that the quality of the games is high.
The Wheelz Casino was designed for smartphone users who prefer playing on touchscreens. It is a browser version, which doesn't require downloading any special app. Most of the modern devices support the game independently of the operating system. Requirements for the productivity of the device are minimal.
Wheelz Casino is building a good reputation because of its excellent variety of casino games. Some of the most popular games are Crazy Genie, Vikings go to Hell, Hot as Hades, Diamond Wild, Gem Rocks, Revolution, and Valley of the Gods. The casino also offers plenty of other casino games to its customers. The table game selection covers all of the expected games, such as Roulette, Baccarat, Blackjack and Video Poker.
Wheelz Casino belongs to Abudantia NV, registered in Curacao, and operating under the jurisdiction of this country. That means the all casino is obligate to adhere to strict rules and regulations in terms of safety and fair gameplay.
Wheelz Casino guarantees to the users for the protection and preservation of the data you give them about yourself. The latest type of SSL encryption which means that your personal and financial data will be perfectly secured here so you can play with no worries.
Safety and security are important and Wheelz Casino uses the latest encryption technology to ensure that all player data is kept safe and secure. All pages of the website are secured by 128-bit SSL, so your confidential information is protected.
Funding your casino account at Wheelz Casino can be done with a long list of currencies and a choice of safe and secure payment methods. The casino accepts Visa, MasterCard, Maestro, Skrill, Neteller, Qiwi, ecoPayz, Yandex Money, bank transfers, and a variety of cryptocurrencies: bitcoin, litecoin, ripple and ethereum. The casino accepts a good group of currencies including USD, CAD, RUB, ARS, INR, PLN, EUR, NOK, CHF and NZD.
At Wheelz Casino, the help is always just a couple of clicks away. The customer support team can be reached via live chat at any time because they are online 24/7 and ready to help you out with anything you need. Customer Support is also always reachable and ready to help you with any kind of problem.